
#119. UTF-8
-
ID: 119
Type: Default
1000ms
256MiB
Tried: 0
Accepted: 0
Difficulty: (None)
Uploaded By:
UTF-8
Description
众所周知由于计算机是美国人发明的,所以一开始只考虑显示英文字母和符号,128个数字完全够用(ASCII码)。
后来推广到世界各地之后,由于其他语言文字需求,需要显示的字符多达数万个,一个字节都存不下了,于是他们扩展了ASCII码,约定了一个固定格式,使用更大的范围表示更多的字符。
于是就有了Unicode码,而作为常用的编码方式UTF8,即为Unicode的一个变种,编码规则如下:
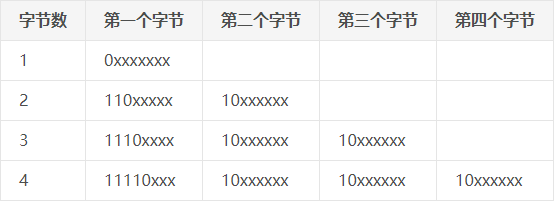
UTF8编码最大的优势在于可变长度编码,对于比较常用的字符,使用更小的数值来表示,占用更少的内存。
这里的编码规则表示,若第一个字节的二进制最高位为0,则后7位的值表示这个字符的Unicode码。
若第一个字节的二进制最高3位为110,则用第一个字节的最后5位和第二个字节的最后6位组合表示一个Unicode码。
以此类推,最多使用四个字节。
你的任务是计算一个字符串中的每个Unicode码值并输出。
Input Format
一行由空格隔开的整数 $a_i$ ($0 \le a_i \le 255$) ,表示字符串中的每个字符,以整数 $0$ 结尾。
数组长度不超过 $10^5$。
Output Format
输出 $x$ 行,$x$ 是字符串中的Unicode码个数,
每一行一个数,第 $i$ 行表示这个字符串中的第 $i$ 个Unicode码。
PS:4869.
65 66 67 0
65
66
67
229 147 136 229 147 136 0
21704
21704
Hint
样例2的数组表示为二进制为:
{11100101B, 10010011B, 10001000B, 11100101B, 10010011B, 10001000B, 00000000B}(二进制表示)。
从字符串开头开始解析,第一个字节为11100101B,以1110开头,使用上表第三行的格式,由当前字节的低4位和后两字节中每个字节的低6位组成Unicode码:0101 010011 001000(二进制),表示为十进制为21704,接下来由于前三个字节被用过了,于是从第四个字节继续解析,一直到字符串结尾(0)。
Source
1816 Online Judge 10.100.0.232